

Black Box Explanation by Learning Image Exemplars in the Latent Feature Space
Exploratory: Social Impact of AI and Explainable ML
Nowadays, Artificial Intelligence (AI) systems for image classification are generally based on effective machine learning methods such as Deep Neural Networks (DNNs). These models are recognized to be “black boxes” because of their opaque, hidden internal structure, which is not human-understandable [1]. As a consequence, there is an increasing interest in the scientific community in deriving eXplainable AI (XAI) methods able to unveil the decision process of AI based on black box models [2]. Explaining the reasons for a certain decision can be very important. For example, when dealing with medical images for diagnosing, how can we validate that an accurate image classifier built to recognize cancer actually focuses on the malign areas and not on the background for taking the decisions?
In [3], we have investigated the problem of black box explanation for image classification. In the literature, such a problem is addressed by producing explanations in forms of saliency maps through different approaches. A saliency map is an image where the color of each pixel represents a value modeling the importance of that pixel for the prediction, i.e., they show the positive (or negative) contribution of each pixel to the black box outcome. Gradient-based attribution methods [4,5] reveal saliency maps highlighting the parts of the image that most contribute to its classification. These methods are model-specific and can be employed only to explain specific DNNs. On the other hand, model-agnostic approaches can explain through a saliency map the outcome of any black box [6,7]. However, these methods exhibit drawbacks that may negatively impact the reliability of the explanations: (i) they do not take into account existing relationships between pixels during the neighborhood generation, (ii) the neighborhood generation may not produce “meaningful” images.
ABELE, Adversarial Black box Explainer generating Latent Exemplars [3], is a local, model-agnostic explanation method able to overcome the existing limitations by exploiting a latent feature space for the neighborhood generation process. Given an image classified by a black box model, ABELE provides an explanation for the classification that consists of two parts: (i) a saliency map highlighting the areas of the image that contribute to its classification, and the areas of that push it towards another outcome, (ii) a set of exemplars and counter-exemplars illustrating, respectively, instances classified with the same label and with a different label than the instance to explain.
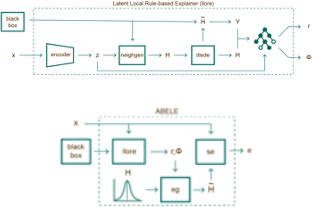
Figure 1
The explanation process of ABELE involves the following steps. First, ABELE generates a neighborhood in the latent feature space exploiting the encoder of the Adversarial Autoencoder (AAE) [8]. Then, it learns a decision tree on the latent neighborhood providing local factual and counter-factual rules ![]() and
and ![]() [9]. Figure 1-left shows this workflow. After that, ABELE generates exemplars and counter-exemplars respecting
[9]. Figure 1-left shows this workflow. After that, ABELE generates exemplars and counter-exemplars respecting ![]() and
and ![]() by exploiting the decoder and discriminator of the AAE. Finally, (Figure 1-right) the saliency map is obtained as the median value of the pixel-to-pixel-difference between the image analyzed and the exemplars.
by exploiting the decoder and discriminator of the AAE. Finally, (Figure 1-right) the saliency map is obtained as the median value of the pixel-to-pixel-difference between the image analyzed and the exemplars.
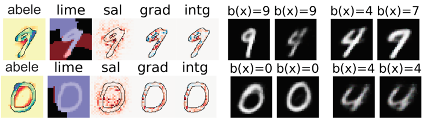
Figure 2
The experiments illustrated in [3] show that ABELE overtakes state of the art methods by providing relevant, coherent, stable and faithful explanations. In Figure 2-left are reported the explanations of a DNNs for the mnist dataset classified as “9” and “0”, respectively. The first column contains the saliency map provided by ABELE: the yellow areas must remain unchanged to obtain the same label, while the red and blue ones can change without impacting the black box decision. With this type of saliency map we can understand that a “9” may have a more compact circle and that a “0” may be more inclined. The rest of the columns contain the explanations of other explainers: red areas contribute positively, blue areas contribute negatively. For LIME, nearly all the content of the image is part of the saliency map, and the areas have either completely positive or completely negative contributions. The other gradient-based explanation methods [4,5] return scattered red and blue points not clustered into areas. It is not clear how a user could understand the decision process with these other explanations. In Figure 2-right are shown two exemplars and two counter-exemplars. We notice how the label “9” is assigned to images very close to a “4” but until the upper part of the circle remains connected, it is still classified as a “9”. On the other hand, looking at counter-exemplars, if the upper part of the circle has a hole or the lower part is not thick enough, then the black box labels them as a “4” and a “7”, respectively.
Written by: Riccardo Guidotti
Revised by: Luca Pappalardo, Francesco Bodria
References
[1] Doshi-Velez, F., & Kim, B. (2017). Towards a rigorous science of interpretable machine learning. arXiv:1702.08608.
[2] Guidotti, R., Monreale, A., Ruggieri, S., Turini, F., Giannotti, F., & Pedreschi, D. (2018). A survey of methods for explaining black box models. ACM Computing Surveys.
[3] Guidotti, R., Monreale, A., Matwin, S., & Pedreschi, D. (2019). Black Box Explanation by Learning Image Exemplars in the Latent Feature Space. In ECML-PKDD.
[4] Simonyan, K., Vedaldi, A., & Zisserman, A. (2013). Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv:1312.6034.
[5] Shrikumar, A., Greenside, P., Shcherbina, A., & Kundaje, A. (2016). Not just a black box: Learning important features through propagating activation differences. arXiv:1605.01713.
[6] Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). " Why should I trust you?" Explaining the predictions of any classifier. In SIGKDD.
[7] Lundberg, M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. In NIPS.
[8] Makhzani, A., Shlens, J., Jaitly, N., Goodfellow, I., & Frey, B. (2015). Adversarial autoencoders. arXiv:1511.05644.
[9] Guidotti, R., Monreale, A., Giannotti, F., Pedreschi, D., Ruggieri, S., & Turini, F. (2019). Factual and counterfactual explanations for black box decision making. IEEE Intelligent Systems.