

Discrimination prevention in data mining
Discrimination consists of unfairly treating people on the basis of their belonging to a specific group. Discrimination often leads denying to members of one group opportunities that are available to other groups. There is a list of antidiscrimination laws designed to prevent discrimination on the basis certain attributes (e.g., race, religion or gender) in various settings (e.g., employment, credit, insurance, etc.). In this sense, the European Union implements the principle of equal treatment for specific protected grounds (gender, racial or ethnic origin, religion or belief, disability, age and sexual orientation) in the access of goods and services or in matters of employment and occupation [1][2]. On the other hand, there are a lot of services in the information society that allow automatic collection of data for data mining purposes. Those data are often used to train association/classification rules in view of making automated decisions, for example, loan and insurance granting/denial, personnel selection, etc. However, if the training data are inherently biased for or against a particular community of citizens (e.g., foreigners), the learned model may infer that just being foreign is a reason for loan or insurance denial, showing a discrimination prejudiced behavior. Discovering and eliminating such potential biases from the training data without harming their decision making utility is therefore highly desirable.
The work presented in this post proposes and implements a discrimination prevention method based on data transformation that can considers several discriminatory attributes and their combinations. The authors also propose and implement some measures for evaluating the proposed method in terms of its success in discrimination prevention and its impact on data quality.
The authors consider two main approaches: (i) direct discrimination prevention and (ii) indirect discrimination prevention. Direct discrimination consists of rules or procedures that explicitly mention minority or disadvantaged groups based on sensitive discriminatory attributes related to group membership. Indirect discrimination consists of rules or procedures that, while not explicitly mentioning discriminatory attributes, intentionally or unintentionally could generate discriminatory decisions. This approach aims to avoid direct and indirect discrimination while maintaining data usefulness for applications on data mining.
The approach
The approach for direct and indirect discrimination prevention can be described in terms of two phases, discrimination measurement and data transformation:
● Discrimination measurement. Figure 1 shows the discrimination detection process on a data set (DB). Direct and indirect discrimination discovery includes identifying α-discrimination rules. To this end, first, based on predetermined discriminatory items in DB, frequent classification rules (FR) are divided into two groups: potentially discriminatory (PD) and potentially non-discriminatory (PND) rules. Second, direct discrimination is measured by identifying α-discriminatory rules among the PD rules by using a direct discrimination measure (elift) and a discriminatory threshold (α). Let α ϵ R be a fixed threshold, a PD rule c is α-protective if elift(c)< α. Otherwise, c is α-discriminatory [4]. Third, indirect discrimination is measured by identifying redlining rules among the PND rules combined with background knowledge by using an indirect discriminatory measure (elb), and a discriminatory threshold (α). For α ≥ 0, a PND rule d is a redlining rule if elb(d) ≥ α [4]. Background knowledge might be obtained from the original data set itself because of the existence of nondiscriminatory attributes that are highly correlated with the sensitive ones in the original data set.

Figure 1. Discrimination discovery process
● Data transformation. It consists of transforming the original data DB in such a way to remove direct and/or indirect discriminatory biases, with minimum impact on the data and on legitimate decision rules, so that no unfair decision rule can be mined from the transformed data. The data transformation is applied on direct and indirect rules detected in the previous stage:
○ Direct rule protection. The proposed solution to prevent direct discrimination is based on the fact that the data set of decision rules would be free of direct discrimination if it only contained PD rules that are α-protective or are instances of at least one non-redlining PND rule. Therefore, a suitable data transformation with minimum information loss should be applied in such a way that each α-discriminatory rule either becomes α-protective or an instance of a non-redlining PND rule.
○ Indirect rule protection. The proposed solution to prevent indirect discrimination is based on the fact that the data set of decision rules would be free of indirect discrimination if it contained no redlining rules. To achieve this, a suitable data transformation with minimum information loss should be applied in such a way that redlining rules are converted to non-redlining rules.
Metrics
Antidiscrimination techniques should be evaluated on two aspects. On the one hand, we need to measure the success of the method in removing all evidences of direct and/or indirect discrimination from the original data set; on the other hand, we need to measure the impact of the method in terms of information loss (i.e., data quality loss). To measure discrimination removal, four metrics have been used:
● Direct discrimination prevention degree (DDPD), this measure quantifies the percentage of α-discriminatory rules that are no longer α-discriminatory in the transformed data set (success of the method). DDPD is defined as:
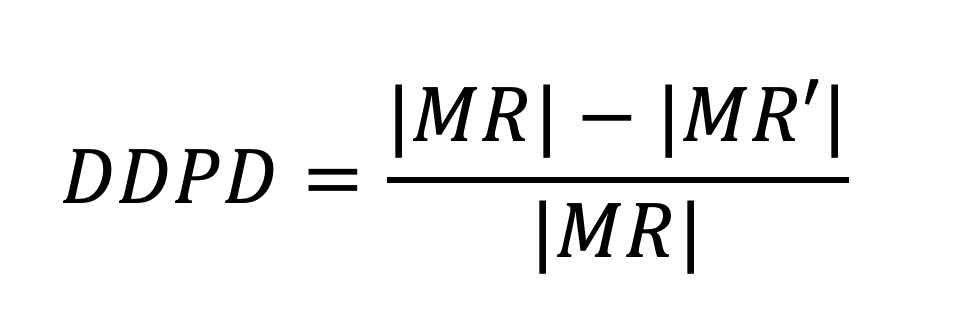
where MR and MR’ are the sets of α-discriminatory rules extracted, respectively, from the original data set and from the transformed data set.
● Direct discrimination protection preservation (DDPP), measures the percentage of the α-protective rules in the original data set that remain α -protective in the transformed data set (data quality). DDPP is defined as:
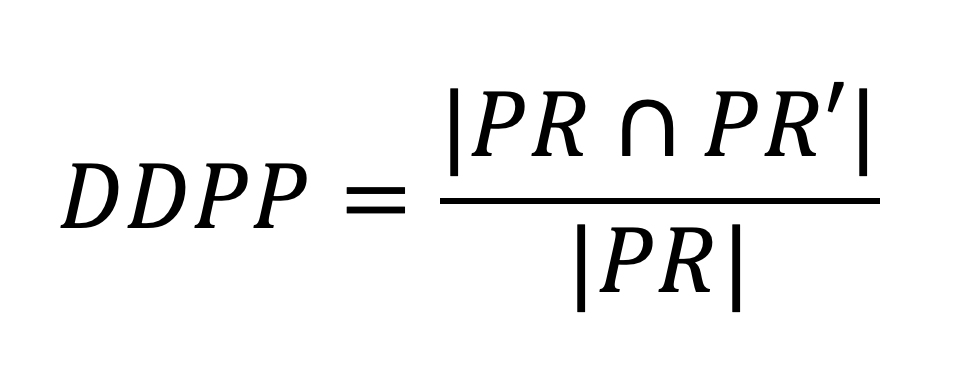
where PR and PR’ are the sets of α-protective rules extracted, respectively, from the original data set and from the transformed data set.
● Indirect discrimination prevention degree (IDPD), quantifies the percentage of redlining rules that are no longer redlining in the transformed data set (success of the method). IDPD is defined like DDPD but substituting MR and MR’ with the set of redlining rules extracted from original and transformed data sets, respectively.
● Indirect discrimination protection preservation (IDPP), evaluates the percentage of non-redlining rules in the original data set that remain non-redlining in the transformed data set (data quality). IDPP is defined like DDPP but substituting PR and PR’ with the set of non-redlining rules extracted from original and transformed data sets, respectively.
Results
We evaluated the implemented algorithms in terms of the proposed metrics. Table 1 shows the scores obtained by the implemented methods on the Adult data set.

Table 1. Adult data set: Measured obtained from the implemented metrics.
The results shown in Table 1 are reported for discriminatory threshold α = 1.1 and Discriminatory Items, DI={Sex=Female, Age=Young}. The results show that the solution achieves a high degree of simultaneous direct and indirect discrimination removal with little information loss.
Conclusions
Along with privacy, discrimination is a very important issue when considering the legal and ethical aspects of data mining. It is more than obvious that most people do not want to be discriminated because of their gender, religion, nationality, age, and so on, especially when those attributes are used for making decisions about them, like giving them a job, loan, insurance, etc. The purpose of this work was to develop a new preprocessing discrimination prevention methodology including different data transformation methods that can prevent direct discrimination and indirect discrimination while preserving the utility of the original data.
The source code [3] and the paper [4] detailing this research are publicly available at Github and CRISES research group webpage, respectively.
[1] European Commission, “EU ANTI-DISCRIMINATION DIRECTIVE,”
[2] Proposal for a Council Directive on implementing the principle of equal treatment between persons irrespective of religion or belief, disability, age or sexual orientation https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A52008PC0426, 2008
[3] https://github.com/CrisesUrv/SoBigData_antidiscrimination
[4] S. Hajian and J. Domingo-Ferrer, "A methodology for direct and indirect discrimination prevention in data mining", IEEE Transactions on Knowledge and Data Engineering, Vol. 25, no. 7, pp. 1445-1459, Jun 2013, ISSN: 1041-4347. https://crises-deim.urv.cat/web/docs/publications/journals/684.pdf
Author: Sergio Martínez (URV)
Exploratory: Social impact of AI, Sustainable Cities for Citizens
Sustainable Goals: (5) Gender equality, (8) Decent work and economic growth, (10) Reduced inequalities