

Disinformation Analysis. A TNA experience
Iknoor Singh, UIET, Panjab University, India | iknoor.ai@gmail.com
TransNational Access @ GATE - University of Sheffield
The generation and spread of disinformation is emerging as a phenomenon of high societal significance. The COVID-19 crisis has given rise to global infodemic and disinfodemic[1]. From fake healthcare treatments to conspiracy theories, daily tens of millions of posts are shared on Twitter, Facebook and other platforms. These can have detrimental effects on public health and hence makes debunking vitally important.
The COVID-19 disinformation can be classified into distinct categories (e.g. medical advice, virus origin etc) and there are no tools which automate this process. The ability to do so automatically is paramount, as fact-checkers can then easily navigate prior debunks related to the relevant topic (eg. medical advice) and therefore help speed up debunking. To address this challenge, I created a new COVID-19 disinformation dataset. The corpus contains disinformation (e.g. false information or misleading posts) debunked by the CoronaVirusFacts Alliance led by the International Fact-checking Network (IFCN). A total of 7787 debunks were crawled from their website, out of which we filtered the English debunks which were then manually annotated and classified into 10 different COVID-19 disinformation categories. The annotated dataset was used to train different deep learning models in order to classify the debunks[2]. We also did an exploratory analysis of the complete dataset and got some interesting insights.
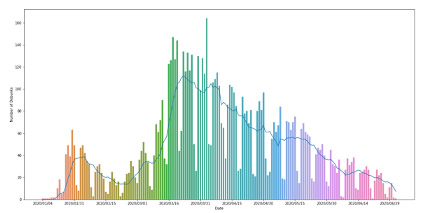
The barplot and rolling average curve illustrate the number of debunks per day from January to June 2020. It’s quite evident that there is a substantial increase in the number of debunks in the month of March and April, reaching a peak value on 3rd April 2020. The graph provides one thing very intriguing, that is 5 continuous peaks followed by a plummet for a couple of days indicating a weekend. Apart from this, India contributed to the highest proportion of debunks with 20%, followed by the United States with 13% and Spain with 8% of all debunks. The dataset was further used to examine the spread of mis- and disinformation. For instance, Facebook and Twitter were the most preferred websites for spreading COVID-19 related disinformation. With respect to types of content, three main disinformation formats have been identified for this study, based on the modality of the content (e.g. text, video, image, audio or press). Post with the textual content is majorly used for sharing misleading information on Facebook whereas for twitter it is video. The type of disinformation media also differs from country to country. To cite an example, video is the most extensively used in India whereas netizens in USA are more inclined to use text and image to disseminate disinformation.
The spread of false or deceptive information in online media has also created the need to quantify the reliability of an article, by checking the authenticity of quoted text as well as verifying the credibility of its respective source. Therefore, I created a tool which automates this process of extracting quotes source pairs from a given piece of text.
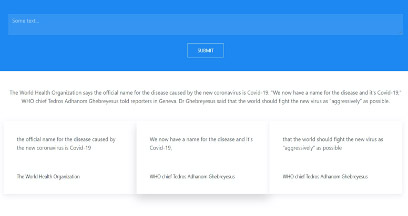
The complete process to get the quotes and the sources can be divided into three main steps. The first step is to extract direct, indirect and mixed quotes from a given piece of text. This was done using Semi Markov machine learning model [3]. The second step is to get all the named entities and resolve any coreferences that might be there in the text. This is an important step because resolving all the coreferences helps in linking all the related entities together. In the third step, a rule-based approach was developed to link each quote to its respective source using the cue verbs. This complete pipeline was used to develop a web application for public usage.
Finally, I am grateful to SoBigData++ for giving me this opportunity to work on this project. I have learnt numerous things and it was an honour to work with people who are at the forefront of natural language processing research. As for the future, I want to explore different ways the quote source extractor can be used for automated fact-checking. I also plan to do a more in-depth analysis of the COVID-19 disinformation corpus.
References
- Kalina Bontcheva et al. 2020. Policy brief 1, disinfodemic: Deciphering covid-19 disinformation. Technical report, United Nation Educational, Scientific and Cultural Organization
- Song, Xingyi, et al. "Classification Aware Neural Topic Model and its Application on a New COVID-19 Disinformation Corpus." arXiv preprint arXiv:2006.03354 (2020).
- Scheible et al. "Model architectures for quotation detection." Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016.