

The Impact of Recommendation Systems on Our Digital Behaviour
Recommendation systems and assistants (in short recommenders) have become integral to our daily interactions on online platforms. These algorithms suggest items or provide solutions based on users' preferences or requests, influencing almost every aspect of our digital experience. From guiding our social connections on platforms like Facebook and Instagram to recommending products on Amazon and mapping routes on Google Maps, recommenders shape our decisions and interactions instantaneously and profoundly.
Unlike specialized AI tools such as medical diagnostic systems or autonomous driving technologies, recommenders are omnipresent across various online platforms. Their pervasive nature allows them to exert significant influence over users' behavior, often leading to long-lasting and unintended effects on human-AI ecosystems. For instance, recommenders can amplify political radicalization processes, increase CO2 emissions, and exacerbate inequality, biases, and discrimination.
Despite the widespread influence of recommenders, our understanding of their impact remains fragmented and unsystematic. Different fields have examined the interaction between humans and recommenders using various nomenclatures, research methods, and datasets, often producing incongruent findings. This lack of coherence calls for a more holistic and structured analysis.
Recently, KDD-Lab published a survey paper that discussed the main recent works that assess the impact the recommenders have on human behavior. The survey focuses on four extensively studied human-AI ecosystems: social media, online retail, urban mapping, and generative AI. These ecosystems represent prototypical instances where the influence of AI is particularly profound, making them ideal for investigating how recommenders shape human behavior.
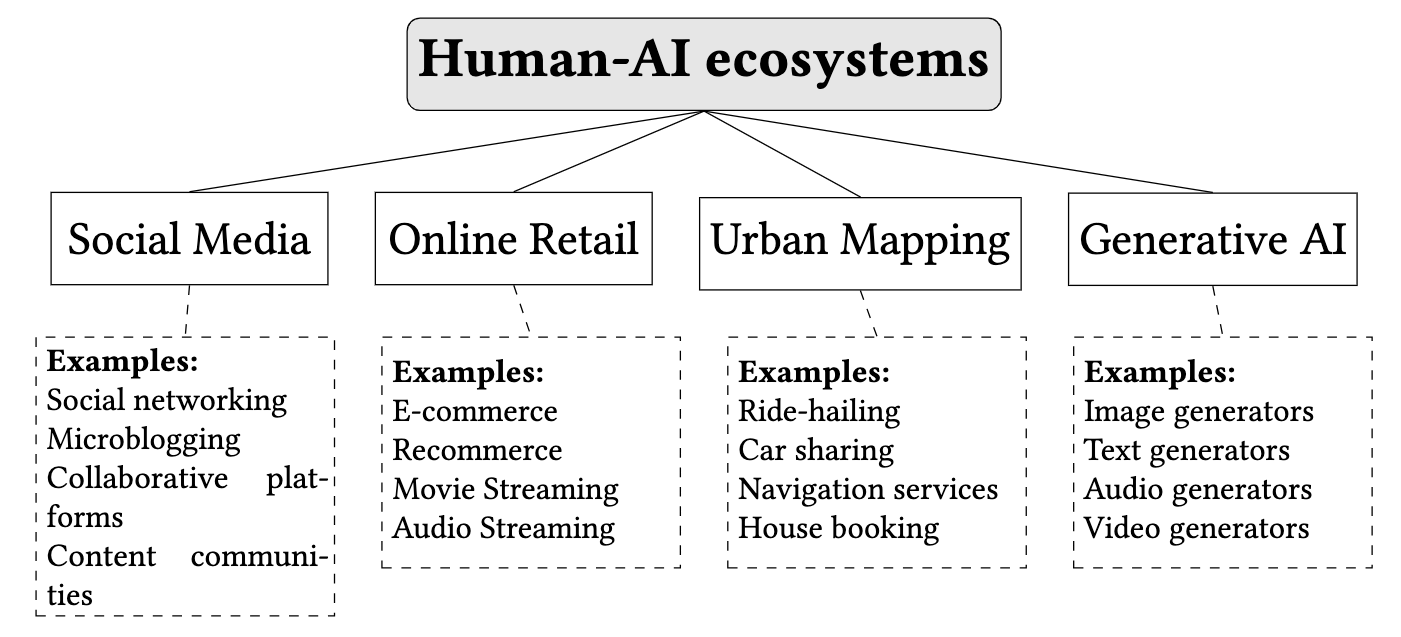
Social media platforms like Facebook, Instagram, Twitter, Reddit, and YouTube use recommenders to filter content and suggest connections. These recommenders significantly influence the information users are exposed to, potentially creating echo chambers and amplifying polarization. Online retail platforms such as Amazon, eBay, Netflix, and Spotify rely on recommenders to suggest products and services. These recommendations drive consumer choices, often determining which products gain visibility and popularity. Urban mapping platforms like Google Maps, Waze, Uber, and Airbnb offer navigation routes and service recommendations. These tools affect not only individual travel behavior but also urban traffic patterns and congestion. Generative AI tools, including chatGPT, DALL-E, and other content creation platforms, generate text, images, audio, and video based on user prompts. These recommenders influence creative processes and the types of content users produce and consume.
Despite the growing attention in the literature, the terminologies used to define outcomes and the methods to measure them remain highly fragmented. To address this, our survey provides a comprehensive overview of recent advances in the literature:
- Categorizing Methodologies: We categorize the methodologies used to assess the influence of recommenders on user behavior, including empirical, simulation, observational, and controlled studies within the four ecosystems.
- Standardizing Terminologies: We standardize the outcomes observed in the literature.
- Disentangling Measurement Levels: We distinguish the levels at which these outcomes are measured, ranging from individual to systemic levels.
- Suggesting Future Research Avenues: We identify technical and methodological gaps and suggest new directions for future research.
This blog post is dedicated to the presentation of methodologies. The following posts of the series will drive you towards the main outcomes found by existing literature in the four human-AI ecosystems.
A taxonomy of methodologies
Our survey categorizes articles within each human-AI ecosystem into empirical and simulation studies, distinguishing between controlled and observational approaches.
Empirical studies derive insights from actual data produced by user-recommender interactions. While they allow for broad generalizations, their ability to draw universal conclusions is limited by specific geographic, temporal, and contextual circumstances. Moreover, reproducing these studies is challenging due to data ownership by large tech companies. Simulation studies, based on model-generated data, offer an alternative when real-world data is unavailable. They allow reproducibility and detailed scrutiny of recommenders' impacts, although they are limited by assumptions that may not reflect real-world dynamics. Both empirical and simulation studies can employ controlled or observational approaches. Controlled studies, such as quasi-experiments and A/B tests, enable the isolation of effects produced by specific variables. Observational studies, on the other hand, offer broader insights but struggle to establish causal relationships and are susceptible to biases.
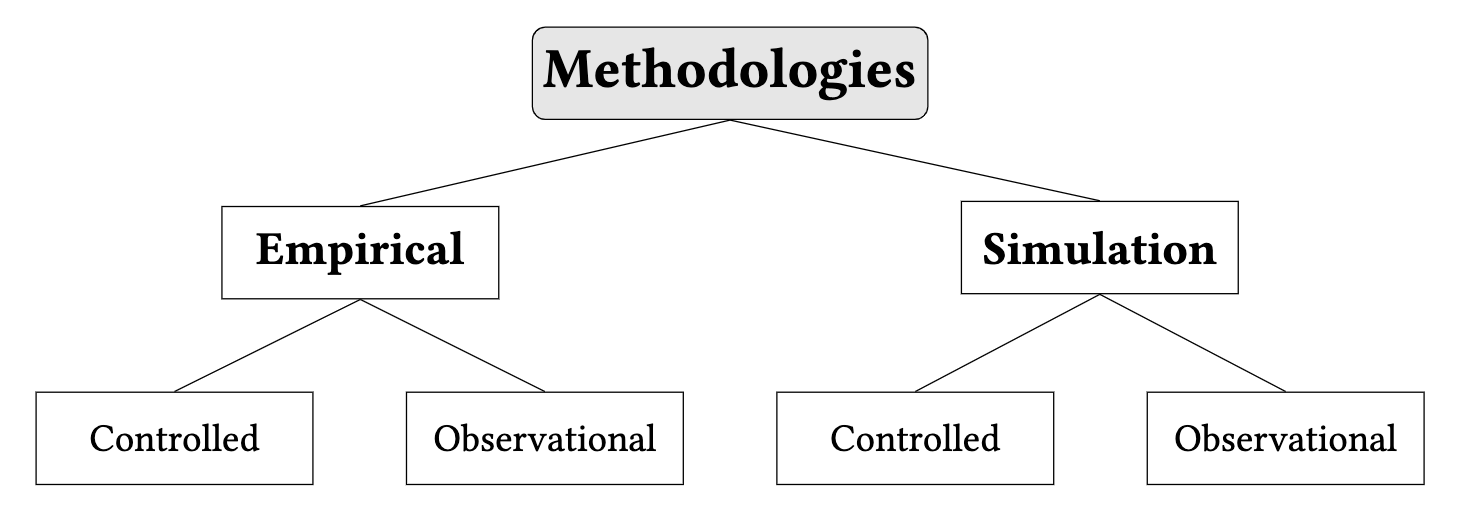
To clarify the differences between these methodologies, let’s consider some prototypical examples. If we have access to data reflecting users’ behavior on a platform and solely analyze this data, we conduct an empirical observational study. However, if only a subset of platform users is exposed to a recommender, and we compare the behaviors of those exposed to those who are not, this is an empirical controlled study. On the other hand, when actual platform data are inaccessible, and we generate synthetic data through simulation tools (such as a digital twin), we conduct a simulation study, which can be observational or controlled, as discussed above. It is essential to acknowledge that quasi-experiments, in which an exogenous element splits the population into two or more groups, according to our definition, must be considered controlled studies. Differently, when an exogenous element does not segment the population into different groups, studies have to be considered observational in their methodological approach. A paper may be classified under different methodologies if it employs two or more of them.
In the next post, we start providing notable examples of studies (and their outcomes) for each methodology.
References
- survey https://www.arxiv.org/abs/2407.01630
- perspective: https://arxiv.org/abs/2306.13723