

Load ready-to-use mobility datasets with ONE line of code!
The new version of scikit-mobility includes a “data module” to access and download ready-to-use mobility datasets and upload new ones to the collection!
As data scientists, we all know the convenience of having ready-to-use datasets at your fingertips. When performing exploratory data analysis (EDA), testing hypotheses, and prototyping models, nothing can beat having preprocessed and reliable datasets for experimentation.
Unfortunately, while there are widely known datasets for tasks such as digit recognition (MNIST), classification (IRIS), and sentiment analysis (Tweets), this is not the case in the human mobility domain.
That’s why we, scikit-mobility’s developers, decided to fill this gap by providing a module to access and download custom-curated mobility datasets, spanning from GPS traces to Origin-Destination matrices and everything in between.
Scikit-mobility (skmob) is among the most used python libraries for human mobility analysis, comprising modules for preprocessing, synthetic traces generation, trajectory data mining, and flow estimation.
Within the new skmob’s release, you can find the data module, which allows you to retrieve standard benchmarking datasets via an easy-to-use interface. The data module API consists of two main functions: list_datasets and load_dataset. The former shows the datasets already available in the repository, the latter retrieves the requested dataset and directly outputs it into a skmob-friendly data structure.
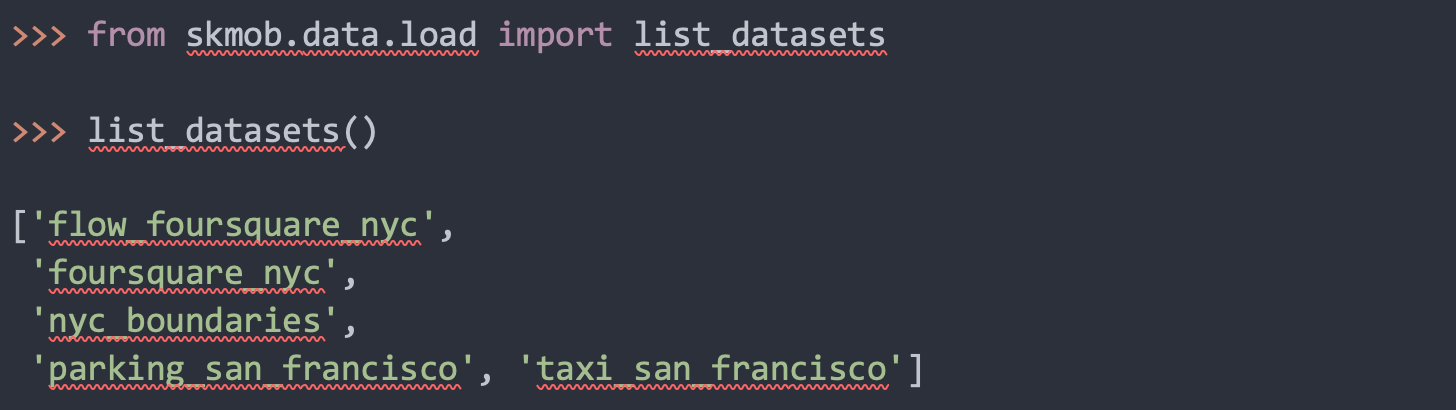
The python code required to list all the available dataset
Furthermore, the data module lets you contribute to the human mobility community by uploading your own datasets and making them available for researchers, industry practitioners, and academia at large. You only need to upload it somewhere publicly accessible on the internet (e.g., through an URL).
The way to expose your uploaded dataset is straightforward, and it is done via a JSON manifest file and a pre-processing python function:
● The JSON manifest describes all the relevant metadata necessary to retrieve your dataset, e.g., the URL at which the dataset is available, name, description, license, maintainers, and citation (if required).
● The pre-processing function contains all the pre-processing steps and data transformations necessary to make your dataset compliant with skmob data structures.
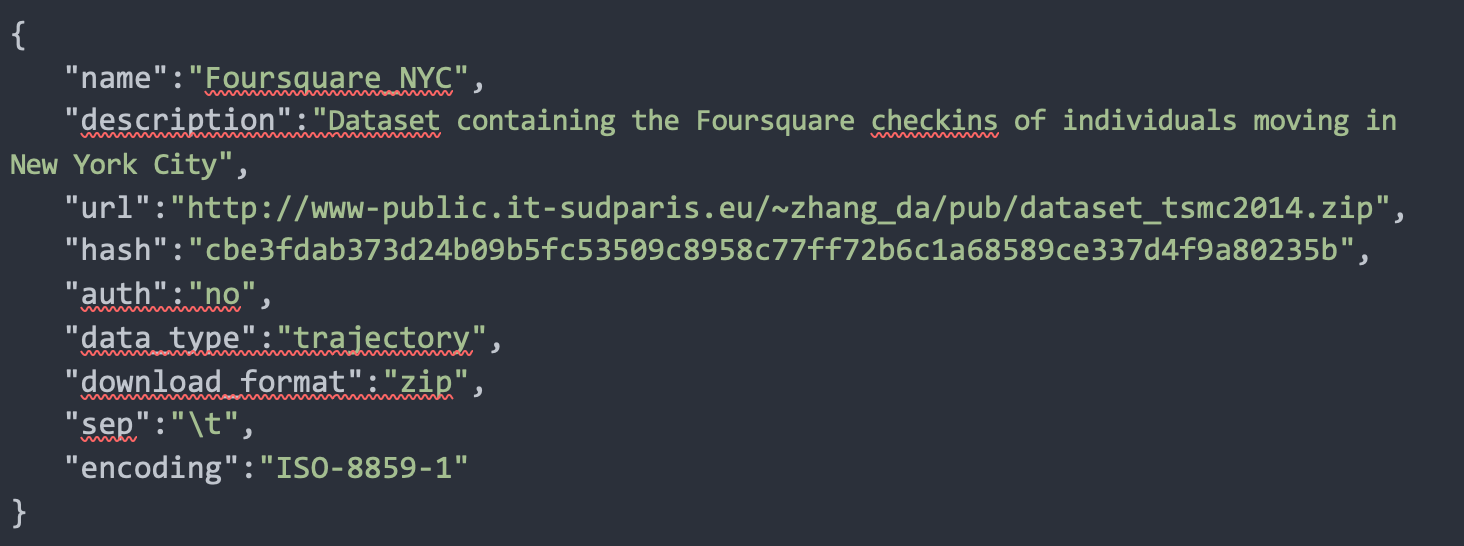
The JSON manifest for the Foursquare NYC dataset
To consume an uploaded dataset, a user simply has to write only ONE line of code calling the load_dataset function with the name of the dataset the user wants to download. This function downloads, pre-processes and transforms your data to ensure scikit-mobility data standards, and make it available for analysis!
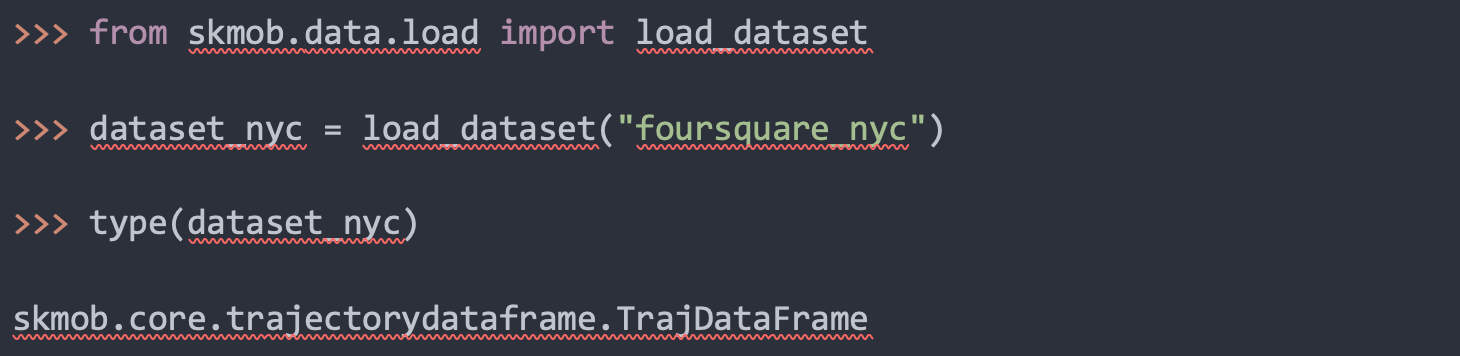
The python code required to load the Foursquare NYC dataset (foursquare_nyc)
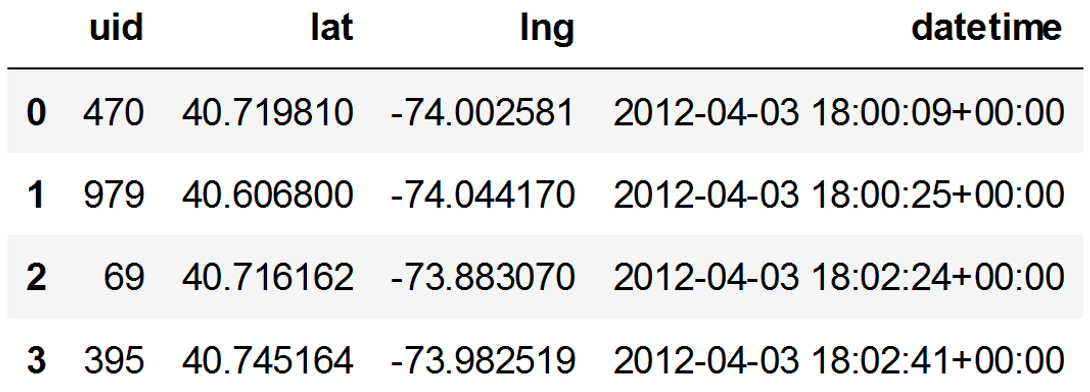
A sample of the Foursquare NYC dataset (foursquare_nyc)
Are you interested in contributing? You may contribute and maybe upload the “IRIS” dataset for mobility! Reach as out @scikitmobility
Data module video tutorial: https://youtu.be/FjJZsaHHuvw
Example notebook: https://jovian.ai/giuliano-cornacchia/the-data-module
Author:
Giuliano Cornacchia, Ph.D. Student in Computer Science, University of Pisa & ISTI-CNR
Exploratory:
Sustainable Cities for Citizens
Item in the Catalogue:
Method: https://ckan-sobigdata.d4science.org/dataset/download_mobility_data_with_scikit-mobility
Sustainable Goals:
Goal 11: Sustainable cities and communities