

The recurring racial bias in AI and Machine Learning
WP2: Responsible Data Science
Recently, there was a case that brought up - once again - the issue of bias in machine learning algorithms.
This is not a new issue per se, as in 2015 a black software developer tweeted about Google’s Photo service labelling him and a friend as “gorillas”. In 2018, a WIRED story highlighted that Google was still struggling to fix the issue with its software, and had resolved to removing the term “gorilla” and other primates from its image labelling lexicon.
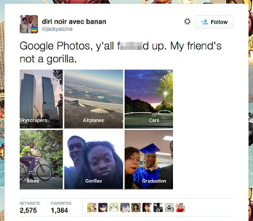
Figure 1: The 2015 tweet by Jacky Alciné
In the last days, a pixelated yet recognizable image of Barack Obama, the former US president, was fed into a tool called Face Depixelizer, which takes a low-resolution image as an input and creates a corresponding high-resolution image through machine learning generative models. The online tool utilizes an algorithm called PULSE - originally published by a group of undergraduate students at Duke University. The output result was the face of a white man. Similar results were obtained with other celebrities, such as Lucy Liu.

Figure 2: Reconstructed face from Barack Obama’s picture. Source: Twitter; Chicken3gg @Chicken3gg 2:14 PM - 20 June 2020

Figure 3: Reconstructed face from Lucy Liu’s face. Source: Twitter; Robert Osazuwa Ness @osazuwa 11:06 PM – 20 June 2020
Actually, the tool was not claiming to be able to reconstruct the real face of the subject (we are aware that some science fiction is still very far from present capabilities of AI and Machine Learning: shorturl.at/fprOZ), but only a “realistic” one. Hence, the algorithm can only try to guess how a person should look. The problem is that the dataset used to train the models or (as in this particular case) to build the output directly is composed of almost entirely (around 90%) white “Caucasian” faces.
The above results demonstrate the already known issue of racial bias in AI, and, in particular, how algorithms perpetuate the bias of their creators and the data they're working with, in this case, by turning everyone into white people.
This is not the first case, and it will surely not be the last one, but as scientists we certainly have the duty to highlight the problem for the sake of science and progress, and to search for possible solutions to it, such as starting to build and use not-biased datasets.
Written by:
Francesca Pratesi: francesca.pratesi@isti.cnr.it
Marco Braghieri: marco.1.braghieri@kcl.ac.uk
Revised by: Luca Pappalardo
References:
https://www.wired.com/story/when-it-comes-to-gorillas-google-photos-remains-blind/
https://www.vice.com/en_us/article/7kpxyy/this-image-of-a-white-barack-obama-is-ais-racial-bias-problem-in-a-nutshell
https://www.theverge.com/21298762/face-depixelizer-ai-machine-learning-tool-pulse-stylegan-obama-bias
https://altdeep.substack.com/p/two-things-you-might-have-missed
https://www.youtube.com/watch?time_continue=30&v=6LYmlWXuW_s&feature=emb_logo