

Sentiment Analysis for Twitter posts
by Ahmed AbuRa'ed from Universitat Pompeu Fabra (UPF)
TNA @ Sheffield University
My PhD research covers a difficult challenge faced by scientists, which is to keep on track whether in their own field, related fields or even new developments of new fields that are appearing due to exponential growth in scientific findings. One way of having a brief overview of a research field is by reading state of the art reports, which usually contain, in condensed form, key information on a topic drawn from different sources.
My main objective is to design a methodology that utilizes machine learning with a set of automatic tools to extract relevant information from scientific papers and generate related work reports. Such reports can be later used as a related work section in a scientific paper or a review of related work in a study field, which serve as a review for scholars.
On the other hand, social media is a good place to voice users’ opinions and influence the way any business is commercialized, government strategy is formed, climate change effects are being addressed or even the prosperity of humanity in general. Public opinion is an important factor in the analysis of how the propagation of information in a large-scale network like Twitter impacts people’s lives.
Twitter is an online social network with over 300 million active monthly users as of the first quarter of 2018. Users on Twitter create short messages called tweets to be shared with other Twitter users who interact by retweeting and responding. Twitter employs a message size restriction of 280 characters or less, which forces the users to stay focused on the message they wish to disseminate. This very characteristic makes messages on Twitter very good candidates for sentiment analysis.
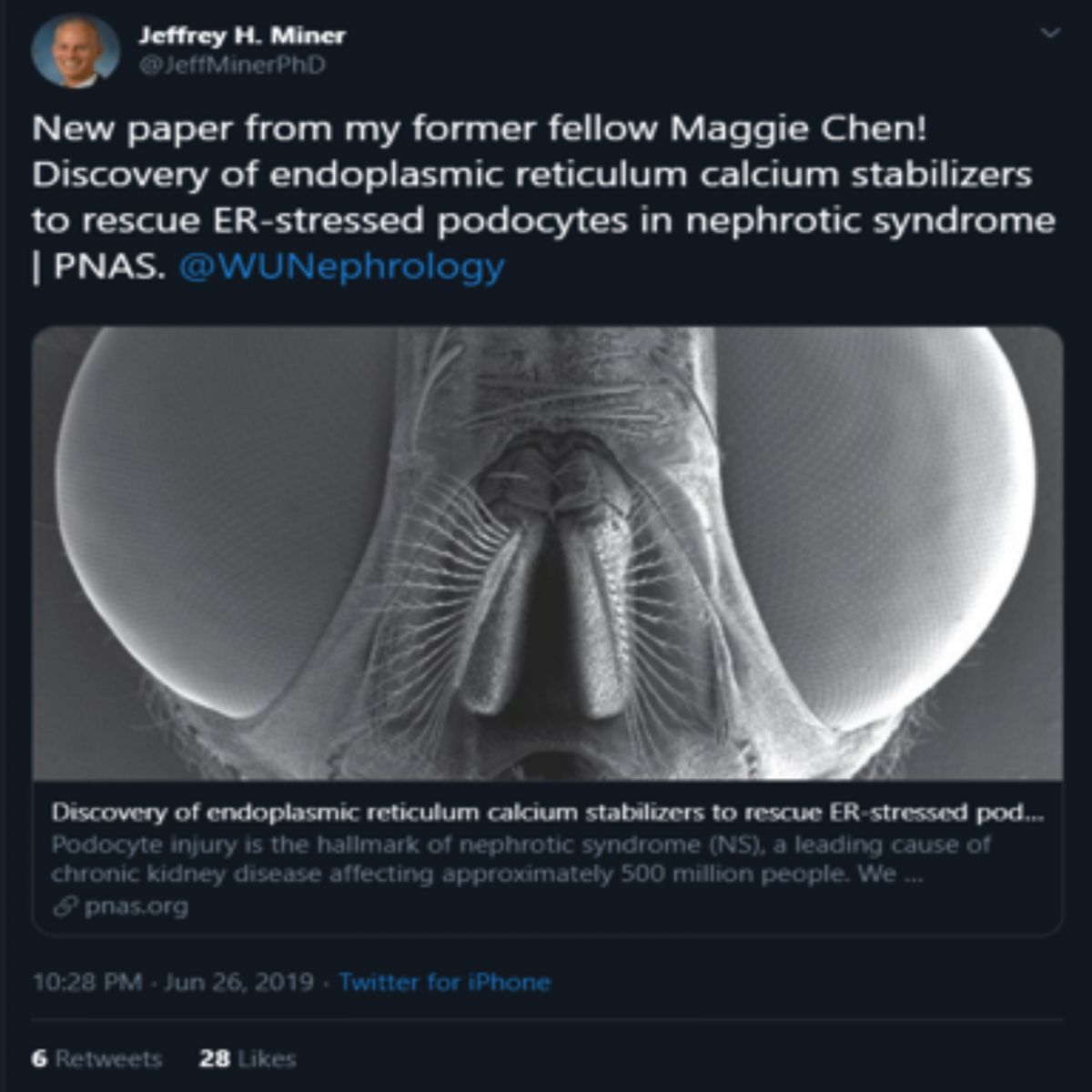
Sentiment analysis of the tweets can be used to determine the polarity and inclination of a vast population towards a specific topic, item or entity. These days, the applications of such analysis can easily be observed during public elections, movie promotions, brand endorsements and many other fields. An example of a positive and negative tweet can be seen below
|
|
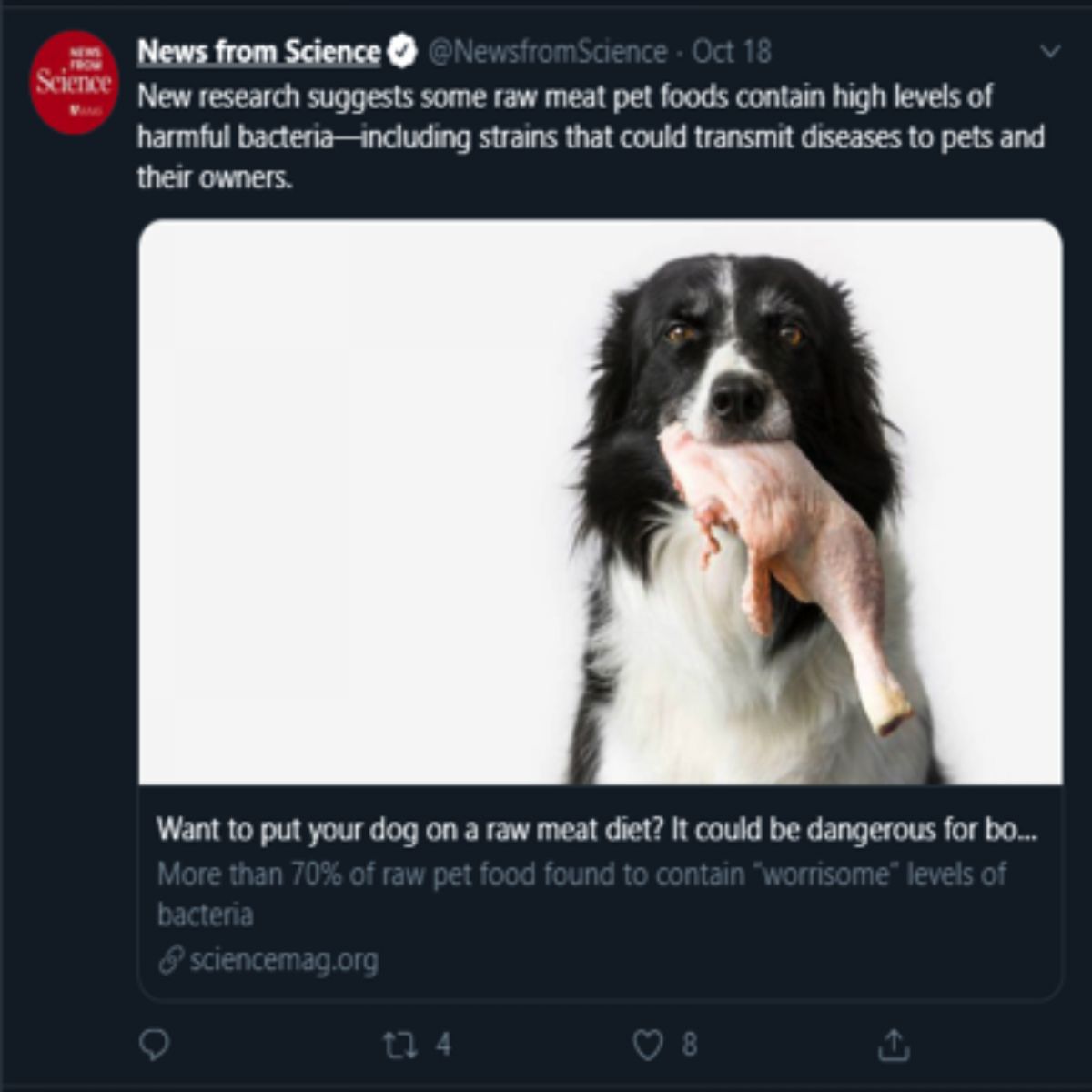 |
| Positive Tweet | Negative Tweet |
Measuring how humanity advance and prospers in science could be done through analysing scientific publications, which are considered permanent records of what we have discovered and invented so far in all aspects of life. That very nature of records documenting all of humanity’s advancements causes a huge amount of information overload in the form of scientific text. with an exponential growth rate over time. However, social media is also a very rich platform to indicate and emphasize such progress and the direction in which humanity is advancing. Such insight could help in tuning the perspective of science and could direct it towards a more productive and brighter outcome.
We use state of the art methods which utilize the GATE framework and its resources. Our approach utilizes a deep-learning approach (Convolutional Neural Network (CNN)) formulating the problem of identifying the sentiment of the scientific tweet as a classification problem (3 classes) which uses a CNN with one input and predicts an output. The input represents the tweet sentences as a Word2Vec representation (embedding layer). On the other hand, the classifier outputs a prediction for each sentence in the tweet. The output label of each tweet sentence can be positive, negative, or neutral.
The network is a feed-forward neural network that models the tweet sentences as a sequence of sentence embeddings, where each sentence embedding is calculated as the averaged word embeddings generated from a pre-trained ELMO model. The network runs three CNN layers over each sentence embedding with a kernel size of 3, 4 and 5, each followed by a ReLU non-linearity, batch normalization, and max pooling. All the results of the max-pooling layers are combined and go through a final fully connected layer with a SoftMax function for the final classification.
For our future work, we will finish implementing and evaluating our approach against a couple of baselines we already implemented using GATE resources. We are also planning to collaborate with Leiden University who have a huge dataset targeting our goal of tweets reflecting opinions on scientific papers, and to test our approach over the new dataset.