Using Machine Learning (Topic Modeling) to Define Product & Geographic Markets: a TNA experience in Pisa
By Stephen Bruestle, PhD. (Economics)
Host: SoBigData.IT - KDD Lab, ISTI-CNR, Pisa, Italy
Most economists do not use clustering. We like to identify a small, fixed number of parameters. And, clustering has many parameters.
Economics will have to change to stay relevant. Developments in data and data science make clustering more practical. Businesses are relying more on clustering. Economists should do the same.
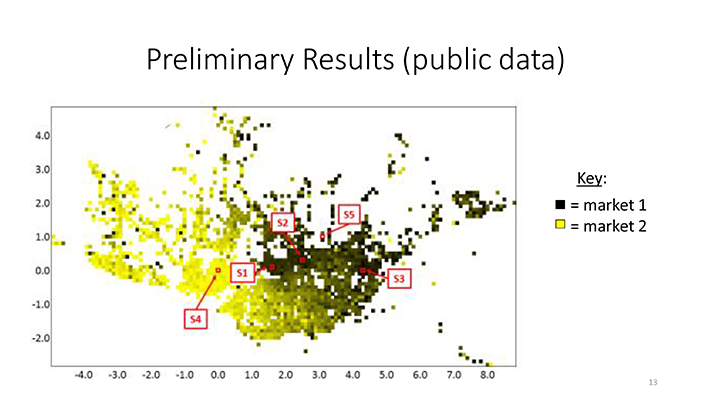
My idea is simple. I will use clustering to solve an economics problem. Specifically, I will use clustering to define markets.
Defining markets is important to antitrust regulators. If you define a market too narrowly, then you get a monopoly. If you define a market too broadly, then you get perfect competition.
A good example of this is the recent Whole Foods merger case in the United States (U.S.). Whole Foods is the largest natural and organic grocery store chain in the U.S. They attempted to acquire Wild Oats, which is the second largest natural and organic grocery store chain in the U.S. The Federal Trade Commission tried to block the acquisition. They defined the relevant market as premium natural and organic grocery stores. Thus, the merger would create a monopoly. Whole Foods went to court to allow the acquisition. They claimed that their market includes the organic aisles of non-specialized grocery stores. Thus, the market would remain highly competitive (Carden, 2009).
Defining markets is important to businesses. For example, in India, the north and west are passionate about cricket. And the south is passionate about soccer. Therefore, the north and west see Adidas and Nike ads featuring cricket players. And the south sees Adidas and Nike ads featuring soccer players (Bhasin, 2017). Therefore, Adidas and Nike have found it useful to segment India into two markets: the north/west, and the south.
Thus, economists developed many statistical methods to define markets. Most of these methods are based on the following: If two goods are in the same market, then they are substitutes for one another. If the price of good A goes up, then consumers will demand more of good B. Therefore, the prices of goods A and B are correlated. And a shock to the price of good A will shock the consumption of good B.
Data scientists have developed a new kind of statistical method for automatically classifying things. They call this field: topic modeling. Usually, topic modeling algorithms classify documents based on the patterns of words in the documents. However, topic modeling has also been used in: classifying genetic sequences based on animal traits (Chen et al., 2010), object recognition in photographs (Fei-Fei and Perona, 2005; Sivic et al., 2005; Russell et al., 2006; Cao and Fei-Fei, 2007; Wang and Grimson, 2008), video analysis (Niebles et al., 2008; Wang et al., 2007), music analysis (Lawrence, 2009), and predicting user tastes and preferences (Marlin, 2004).
In my Short-Term Scientific Mission to Consiglio Nazionale delle Research (CNR) in Pisa Italy, I used topic modeling to classify consumer segments into markets based on their transactions.
In this project, I am developing a new application of Latent Dirichlet Allocation (LDA). LDA is the standard and the most common topic model. Blei et al. (2003) categorized documents based on the contextual patterns of text. I categorize consumer segments into markets based on the contextual patterns of purchases.
It makes sense to use LDA to define markets because LDA has three useful properties. First, I can motivate the LDA model as if it were an economics model for defining markets. The LDA model is general enough so that it applies to any market structure. Second, consumer segments can be classified in the same way that LDA classifies documents. It is an isomorphic problem, which means that the two problems have a structure-preserving one-to-one correspondence. Third, I can set up market data to fit LDA. Specifically, I am using data derived from SoBigData’s Well Being and Economy Database.
The data is proprietary from Coop. Coop is one of the largest supermarket chains in Italy. The data is at the transaction-level. It includes prices and quantity of each product for each transaction. And it tracks consumers across multiple stores.
It is becoming more common for companies to gather this type of data.
Yet, it is rare for a big corporation to allow academics to gain access to this type of data.
I also benefited from talking with the data scientists at CNR in Pisa.
Data scientists and economists have a lot in common. We both develop and apply statistics. We both answer policy relevant questions. We both use the scientific method and large datasets to understand how the world works.
The difference is the focus. Data scientists focus more on the empirics. Economists focus more on combining empirics and economic theory.
I found that my discussions with the data scientists at CNR in Pisa to be invaluable. They challenged me. This led to stronger economic theory.
I am eternally grateful. And, I hope to do more collaborations with data scientists in the future.